
1. 교육AI의 시작 : 지식추적(KT)의 개념
지식은 서로 분절되어 있지 않고 서로 연결된 유사성을 지닌다. 이에 따라 한 개념에 대한 이해도를 바탕으로 다른 개념의 이해도를 추론해볼 수 있다. Knowledge Tracing 은 이렇게 한 문제를 통해 다른 문제를 맞출 수 있는 확률을 추론하는 방법이다. 앞에 심층학습을 의미하는 Deep Knowledge Tracing 은 딥러닝 알고리즘을 이용해 학습자의 퍼포먼스를 바탕으로 학습자 전체 지식 수준을 평가하는 모델을 지칭한다
| DKT를 활용한 적용 분야 | 문제 정답 여부를 통한 학습자의 지식 수준 평가 |
| 지식 수준 평가를 통한 최적합 문제 추천 | |
| 지식 이해 수준을 높일 수 있는 최고 효율 학습 과정 추천 등의 학습 모델을 구성 |
.
2. DKT의 핵심 딥러닝 알고리즘 : 시계열 데이터 처리 알고리즘
학습자의 지식을 추적하기 위해선 딥러닝 모델 중에서도 시계열 데이터(순차)를 다룰 수 있는 알고리즘이 필요하다. 이에 따라 크게 RNN(순환 신경망) / LSTM(long short term memory) / GRU(gated recuttent unit) 알고리즘을 활용한다.

3. DKT의 데이터 임베딩
데이터 임베딩이란 사람이 쓰는 자연어 및 비정형 데이터를 기계가 이해할 수 있는 숫자의 나열인 벡터로 바꾸는 과정이다. DKT 모델에서는 가장 기본적으로 문제의 정답여부에 대한 데이터를 통해 다음 문제에 대한 정답 여부를 추론하는 데이터를 가장 많이 사용하기 때문에, 문제의 종류 / 문제의 정답 여부 / 문제의 번호 등의 속성을 원 핫 인코딩으로 다루는 경우가 많다. 가장 기본적인 DKT 원핫 인코딩의 방법을 살펴보자

문제의 종류는 4가지 (더하기 / 빼기 / 곱하기 / 나누기) 가 있고, 문제의 정답여부는 2가지 (맞음 / 틀림) 인 자료를 원핫인코딩으로 표현한다고 가정해보자. 이 데이터는 총 8가지(4*2) 벡터에 원핫인코딩 할 수 있다. 아래의 예시와 같다.
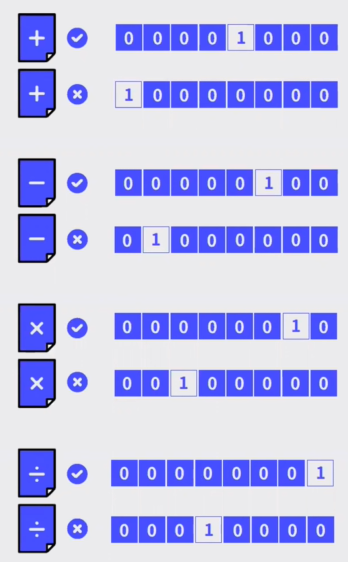
곱하기 문제를 맞았다면 (0,0,0,0,0,0,1,0)으로 / 더하기 문제를 틀렸다면 (1,0,0,0,0,0,0,0) 로 표현할 수 있다. 다만 이렇게 원 핫 인코딩으로 표현할 경우 문제수가 늘어날때마다 벡터값이 기하급수적으로 늘어나, 효율적 표기라고 말하긴 힘들 것이다.
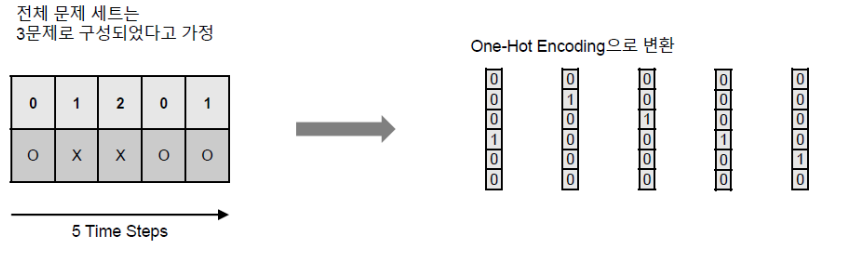
위의 사례도 마찮가지의 원 핫 인코딩이다. 문제 데이터 셋은 총 3문제(0,1,2로 표현), 정답 여부는 2가지(맞음, 틀림) 일 때 각 상태를 오른쪽과 같이 표현할 수 있다. 3*2=6가지의 벡터항으로 원핫인코딩 할 수 있다.
4. DKT 알고리즘 추론
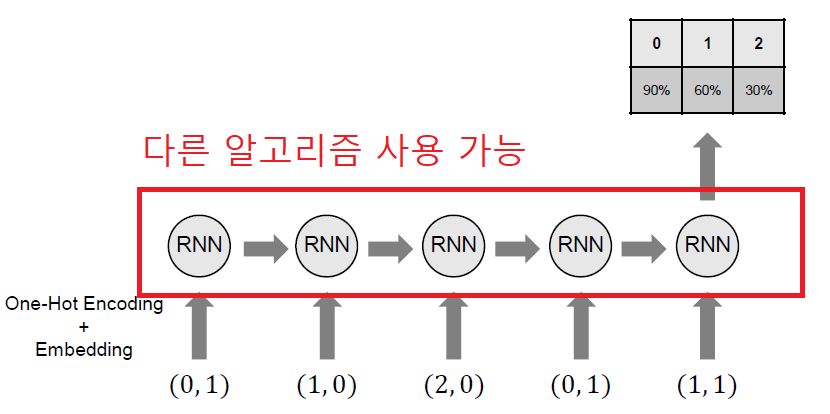
데이터 임베딩이 완료되면 해당 데이터를 바탕으로 심층 지식추적 추론을 실시한다. 위 문제의 경우 5문제를 푼 데이터 셋을 통해 다음 6번째 문제에 대한 정답 확률을 구하는 상황이다. 위 논문의 예시에서는 RNN 알고리즘을 사용하였는데 다른 알고리즘(LSTM / GRU 등)을 사용할 수 있다.
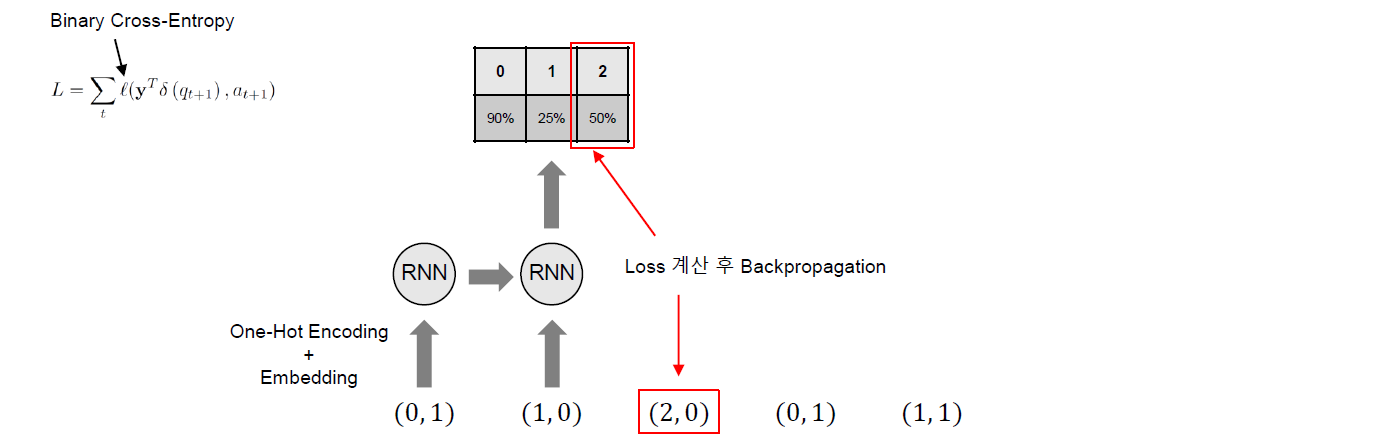
각 단계별로 순차적으로 학습을 진행하는데, 이때 핵심은 전 단계에서 추론한 다음 문항에 대한 정답률과 다음 문항에 실제 정답과의 오차가 최소가 되도록 Backpropagation(오차 역전파)하는 것이다. 손실함수로 binary cross-entropy 를 사용하는데, 수식의 내용을 살펴보면 도움이 된다.

**오차역전파(Backpropagation)
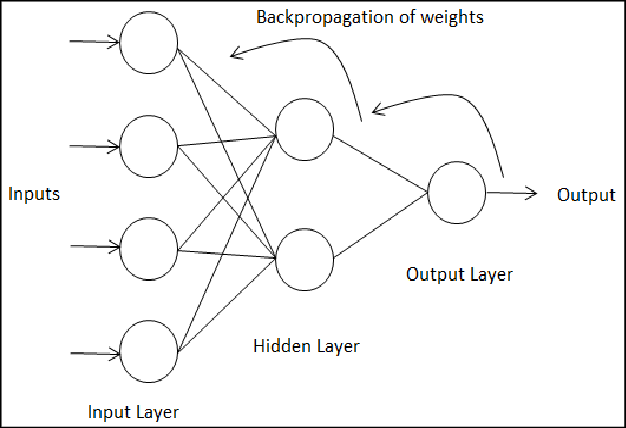
실제 신경망은 입력 > 은닉층처리(가중치의 선형합)>출력(활성화함수)로 진행된다. 하지만 인공신경망의 학습 단계에서는 정답과의 오차를 최소화하는 최적의 가중치와 임계값을 알지 못한다. 따라서 학습의 시작 단계에서는 난수의 가중치와 임계값으로 시작해서 한 학습이 끝나면 그 훈련 데이터의 정답과 비교해 오차를 최소화하는 방향으로 역으로 가중치와 임계값을 조정한다. 따라서 인공신경망의 학습 방향은 출력(가중치, 임계값 조절) > 은닉층처리(가중치, 임계값 조절) 의 역방향으로 진행된다. 이를 오차 역전파라고 한다.
RNN에서는 이 역방향 가중치 조절 과정이 매 순차 데이터 처리에서 일어나고 있다.
5. DKT 연구의 시사점 및 유의점
-학습자의 퍼포먼스를 바탕으로 학습자의 지식 수준을 평가할 수 있다는 건 1:1 맞춤교육이 실현된다는 뜻
-또 같은 문제를 학습해도 문제를 학습하는 순서에 따라 학습효율성이 달라진다는 것은 시사점이 크다. 학습자를 최적으로 학습시키는 과정을 찾는 것은 교육의 이상에 다다르는 것
-다만 아직 갈길이 멀고 연구가 많이 필요하다고 느껴짐
-현재의 연구들이 주로 집중하고 있는 데이터는 문제의 정답 여부인데, 이것만으로는 학습자 고유의 특성을 다 파악했다고 할 수 없음. 같은 순서로 풀었다고해서 다 같은 지식 수준을 가진 것이 아님. 10명의 학습자가 있으면 10명 모두 다른 개별 특성을 가지고 있기 때문.
-따라서 더 다양한 개별화 특성 변수를 수집해야 함. 예를 들면, 문제를 푸는데 소요된 시간 / 정답과 유사한 오답을 골랐는지 전혀 상관 없는 오답을 골랐는지 여부 / 성별, 문화권 등 학습자에 대한 개별적 배경 데이터 등의 데이터가 필요할 것으로 보임
-원 핫 인코딩의 한계를 극복할 수 있는 새로운 데이터 임베딩 방법 필요. 원 핫 인코딩은 과도하게 백터를 늘려야하는 문제가 있음. 예를 들면 총 1000개의 문제로 데이터 셋을 만든다면, 2000개의 데이터 벡터가 필요함. 문제의 수가 늘어날수록 표현해야할 무의미한(주로 0으로 표현된) 벡터값이 늘어남.
'교육은 한 사람의 인생을 바꾼다 > AI교육' 카테고리의 다른 글
| DKT의 개선 방향 (0) | 2023.02.05 |
|---|---|
| 인공지능교육 : 지식 추적(KT)에 대한 배경 지식 (0) | 2023.02.04 |
| 인공신경망의 이해 : RNN ( 순환 신경망) (0) | 2023.01.27 |
| 인공신경망의 이해 : 인공신경망의 작동 원리 (1) | 2023.01.26 |
| 인공신경망의 이해 : 생존이라는 강화학습 (0) | 2023.01.25 |




댓글