
<<타이타닉 생존자 예측 모델>>
1. 모델 생성
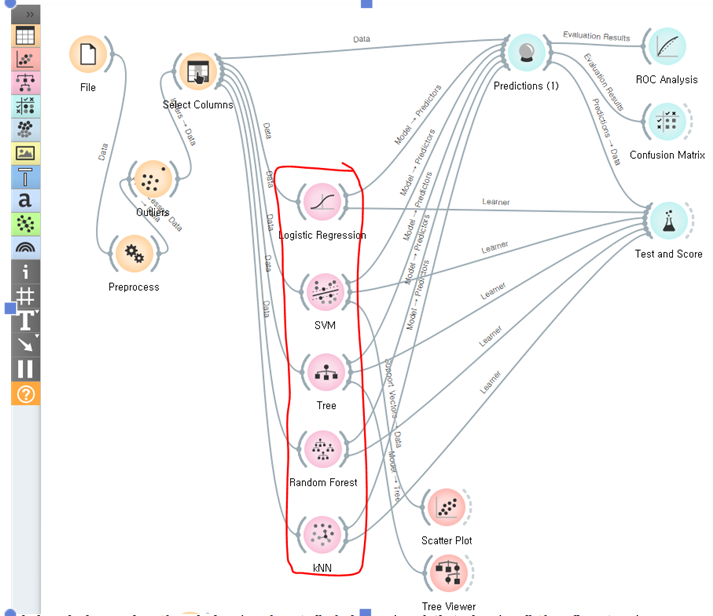
위와 같이 로지스틱 회귀 / 서포트백터머신 / 결정트리 / 랜던포레스트 /k-Nearest Neighbor 의 5가지 지도학습 알고리즘을 활용하여 타이타닉 생존자 예측 모델을 테스트 했습니다.
2. 학습 / 예측

현재 5가지 모델 중 random forest 모델의 area under ROC curve / accuracy / f1 score / 정밀도 / 재현율이 가장 높습니다. Tree 모델보다 근소하게 높습니다. 따라서 타이타닉 생존자 예측에 가장 최적화된 모델은 random forest 모델일 것으로 예상됩니다.
3. 평가

random forest 와 Tree 모델을 비교해보면 TN/FN 영역에서는 랜덤 포레스트가, FP/TP 영역에서는 트리 모델이 좀 더 우위인 것을 확인할 수 있습니다. 두 모델을 같이 사용해도 좋을 것 같습니다. 둘 중 하나만 사용해야 한다면 어떻게 해야할까요?

test and score 점수를 보아도 모델의 성능을 쉽게 비교할 수 있습니다. radom forest 모델이 나머지 네 모델이 비해서 AUC 영역 비교에서도 압도적 성능을 보입니다. 여기에선 TREE 모델의 성능이 저조합니다. 오히려 비교대상은 로지스틱 회귀 모델이었지만, 그래도 6:4 정도로 앞서고 있습니다. 따라서 하나만 사용해야 한다면 랜덤 포레스트 모델을 사용하는 것이 확률적으로 최적일 것입니다.
4. 최적화 모델을 새로운 테스트 데이터에 적용
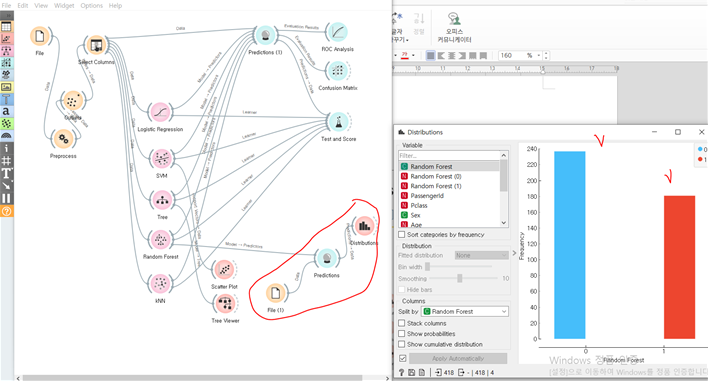
최적 모델인 랜덤 포레스트를 새로운 테스트 데이터에 넣어서 예측해봤습니다. 승객의 56.7% 237명은 살아남지 못할 것이고, 나머지 181명만 살아남을 것으로 분석하고 있습니다.
<직접 고른 데이터로 군집화 하기>
1.고른데이터: Mall Customer
위 데이터는 쇼핑몰 사용 고객 200명에 대한 성별 / 나이 / 연수입 / 소비지수의 feature를 가지고 있는 데이터입니다. 본래의 목적은 이 데이터를 할용해 소비지수를 중심으로 하는 군집을 구성하고 그 결과로 소비지수에 영향을 미치는 요소들을 확인해보는 것이었습니다.
2. EDA

현재 위와 같이 간단하게 EDA를 진행해 데이터 군집화를 하기 전 데이터에 대한 INSIGHT를 구해보았습니다. 가장 특이했던 점은 Correlation 위젯을 통해 feature간 상관관계를 보았을 때, 밀접한 상관관계가 없었다는 점입니다. 그나마 age 가 피어슨상관계수로 –0.3 정도였습니다. 이것은 약한 정도로 나이가 적을수록 많은 소비를 했다 정도로 해석됩니다.
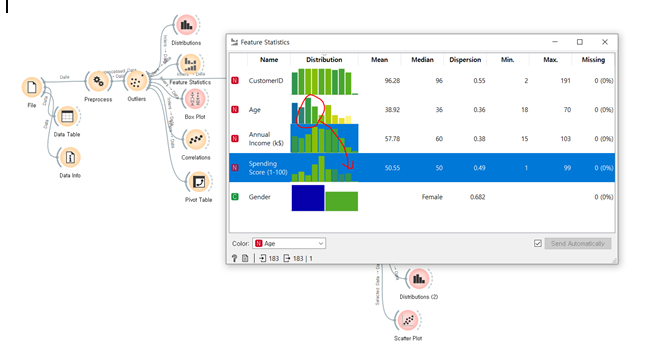
이후 feature statistic 으로 살펴보니 저,중나이대가 spending score 상위권에 연관되고 있는 것을 확인했습니다. 하지만 적은 유사도였습니다.

필터를 전체로 놓고 돌렸을 때, 가장 높은 상관관계는 놀랍게도 연수입과 커스터머아이디였습니다.

이는 연수입에 따라 커스터머이아디 번호를 부여했기 때문으로 보입니다. 여기에서 벌써 뭔가 공들이지 않은 데이터라는 느낌이 들었고, 원하는 결과를 얻지 못할 것 같은 기분이 들었습니다...만 실패는 성공의 어머니이기에 한번 계속해봤습니다.
3. 모델 생성
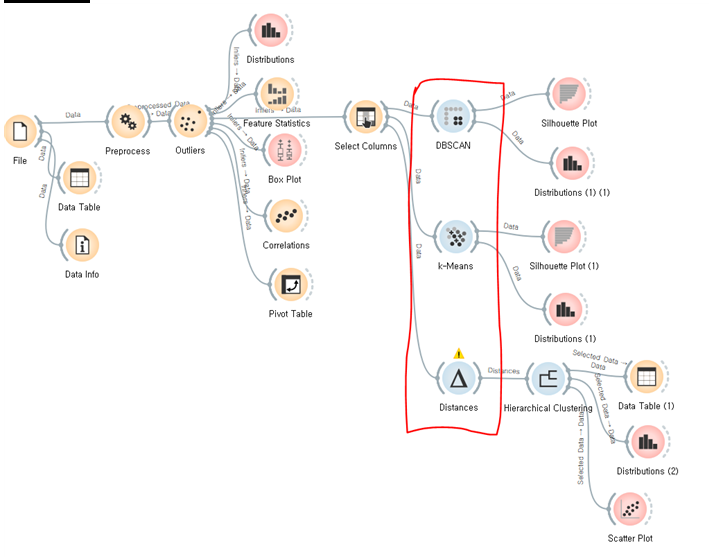
데이터가 워낙 상관관계가 적어서 가능한 모든 방법을 다 써보고 그 중 가장 결과치가 좋은 데이터를 고르기 위해 분할적 군집화(밀도기반, 중심기반) / 계층적 군집화를 모두 사용해보았습니다.
4. 군집화 모델 해석 및 평가

군집화 결과를 분포도 위에 표현해보았다. 각각 2~3개의 군집으로 나눠졌는데, 아주 유의미한 차이를 보이진 못하고 있다. 그나마 군집간 분리도가 선명한 것은 DISTANCES 위젯을 활용한 계층적 군집화이다.
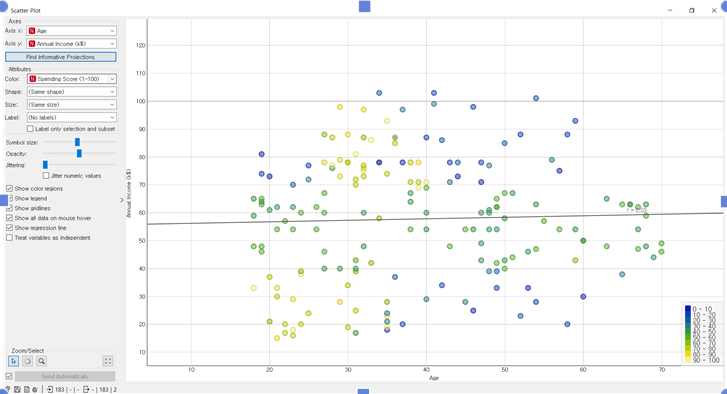
이를 바탕으로 산포도 위에 표현해보았는데, 가로축은 나이/ 세로축은 연수입 / 색깔은 소비지수이다. 데이터의 분포 정도도 그렇고, 회귀직선또한 거의 수평에 가까운 것으로 보아서 유의미한 상관관계를 발견하기 힘들다.
<<텍스트 마이닝>>
1. 데이터 수집

제가 고른 데이터는 2016 미국 선거 트럼프 vs 힐러리 트윗데이터입니다. 6444개의 텍스트 데이터로 되어있고 작성자는 2명 힐러리 / 트럼프입니다.
2. 전처리

word cloud 로 사용된 단어들을 확인했는데 https 등의 인터넷 주소가 가중치를 높게 받아, 전처리 시 remove url + pares html 했습니다. 또 학습은 70% 데이터로 평가는 30% 잔여 데이터로 하기 위해 데이터 샘플러를 사용했습니다.
그래도 데이터의 개수와 변수 항목이 너무 많아서 도저히 처리를 못해서 다루고자 하는 핵심 feature author 와 content만 남기고 나머지는 ignore 처리했습니다.
3. 모델생성
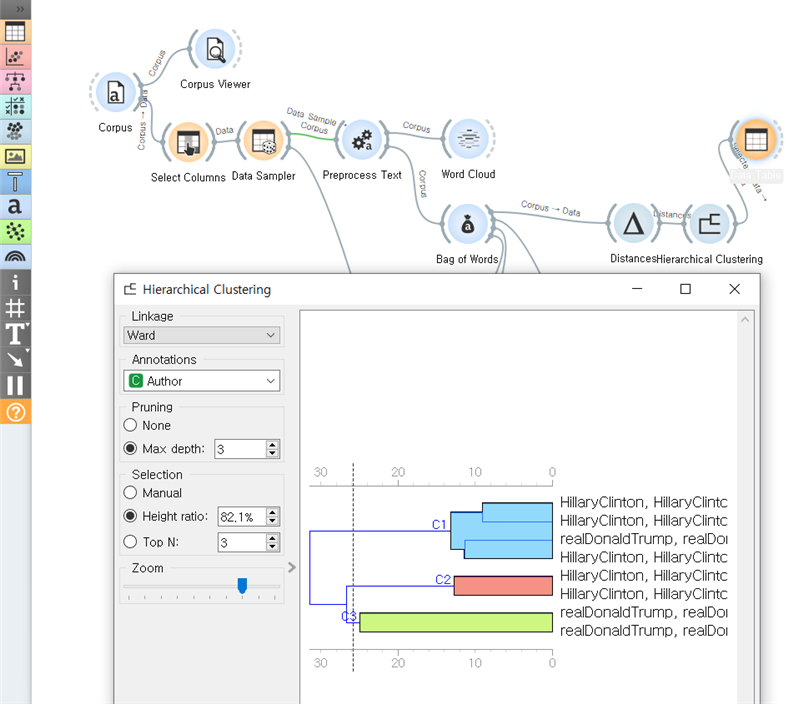
글의 사용된 단어를 분석하여 군집화하는 모델입니다. 전반적으로 잘 분류가 되나 싶었지만 몇몇은 힐러리와 트럼프가 섞이는 부분이 있었습니다.
4. 학습/ 분류
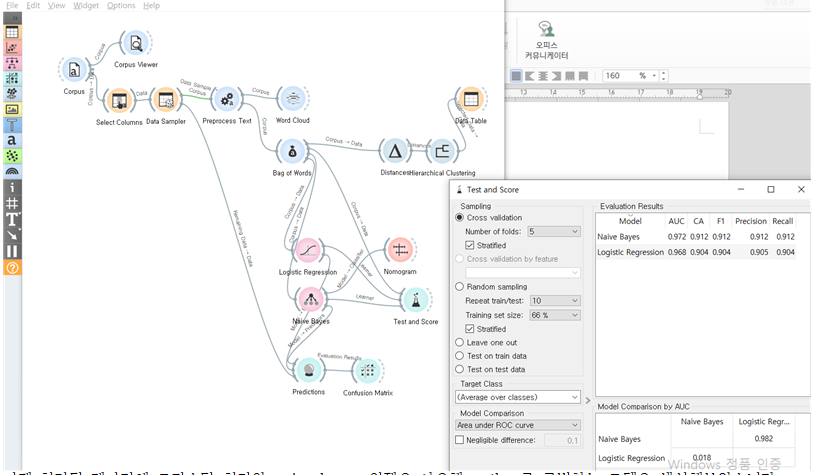
이제 처리된 데이터에 로지스틱 회귀와 naive bayes 위젯을 사용해 author를 구별하는 모델을 생성해보았습니다.
test and score 결과로 보았을 때, naive bayes 모델이 더 적합한 것으로 보입니다.
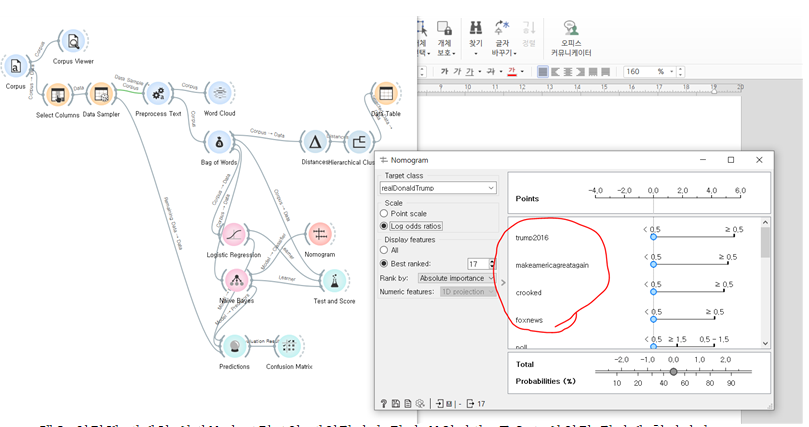
모노그램을 연결해 자세히 살펴보니 트럼프의 파워단어가 많이 보입니다. 중요도 상위권 단어에 힐러리가
사용한 단어들이 많이 없습니다. 2016 대선에서 트럼프의 강한 위기의식이 제고가 효과적이었던 것으로 보입니다. make america great again / crooked(비뚤어진) / trump2016 짧으면서도 강렬합니다.
5. 평가
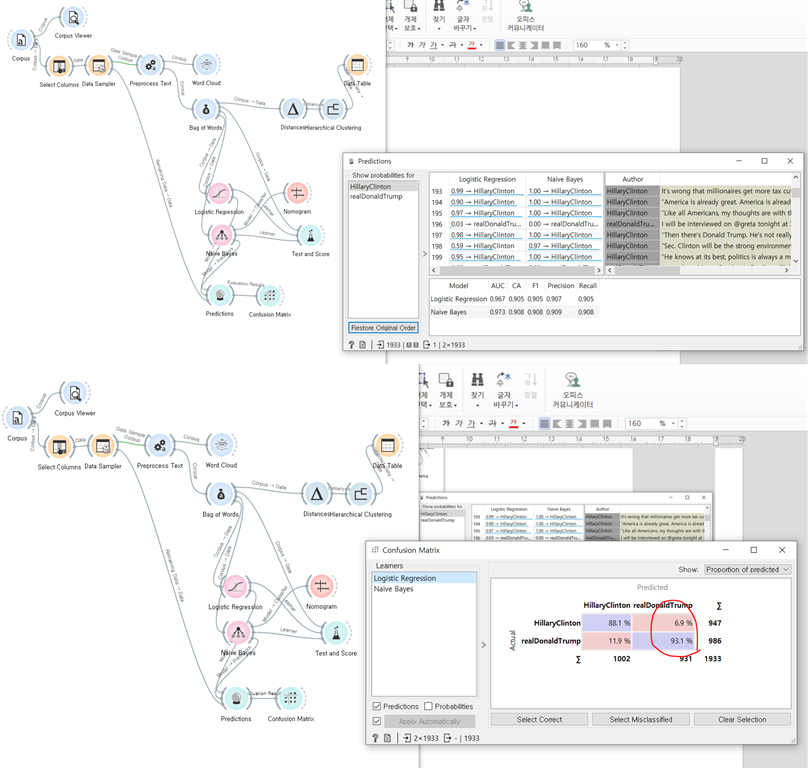
실제로 데이터 샘플러에 의해 남겨진 30%의 데이터를 prediction에 넣어 확인해봤습니다. 컨퓨전 메트릭스를 통해 100분율로 환산해 보니, 로지스틱 회귀 방식도 도널드트럼프의 트윗을 판별하는 부분에서 꽤 정확해서 유용하다고 느꼈습니다. 실제 적용한다면 힐러리의 트윗은 naive bayes로 / 트럼프의 트윗은 로지스틱 회귀로 분석하는게 효과적일 것으로 보입니다.
'교육은 한 사람의 인생을 바꾼다 > AI교육' 카테고리의 다른 글
| 완전 초짜 ORANGE 3 : 연관 분석 (0) | 2021.09.06 |
|---|---|
| 완전 초짜 ORANGE 3 : 지오코딩 (0) | 2021.09.05 |
| 완전 초짜 ORANGE 3 : 비지도학습 군집화 위젯 (0) | 2021.09.03 |
| 완전 초짜 ORANGE 3 : 비지도학습(차원축소) (0) | 2021.09.02 |
| 완전 초짜 ORANGE 3 : 비지도학습 군집화 기초 (0) | 2021.09.01 |




댓글