
▷시스템 제작 과정
| AI 문제 확인 | AI 솔루션 확인 | AI 솔루션 설계 | AI 솔루션 개발 | 평가 및 피드백 |
| -AI로 해결 가능한 문제 찾기 EX) 주택가격 |
-문제 해결 방법 찾기 -다양한 분석틀 이용 |
-구체적 '안' 설계 -어디에서 데이터를 수지할까? 데이터 수집의 한계 |
-오렌지3 워크플로우 제작 | -새로운 데이터에 적용 -결과 확인 |
▷시스템 제작 예제 확인
1) 네트워크 분석 모델

네트워크 분석은 군집화와 연결성이 좋다. 일반적인 데이터도 Distances(계층적 군집화 모델)로 instance간 거리(유사도)를 수치화하면, 네트워크 위젯으로 분석하고 표현할 수 있다. 또한, Distances 위젯으로 분석했기 때문에 Distance Matrix나 Hierarchical Clustering 위젯 등으로 시각화 할 수도 있다.
2) 이미지 분석 모델

일반적인 이미지 상태에선 어떤 분석도 할 수 없다. 컴퓨터는 숫자만 알아들으니까 숫자로 바꿔주는 작업이 임베딩. 위의 분석 모델은 두 이미지 데이터군을 모두 임베딩한 후 Neighbors 위젯으로 인접한 2개의 이미지를 고르게 해주는 시스템이다. Image Embedding 과 Neighbors 위젯의 연결을 기억하자.
3) 텍스트 마이닝 모델
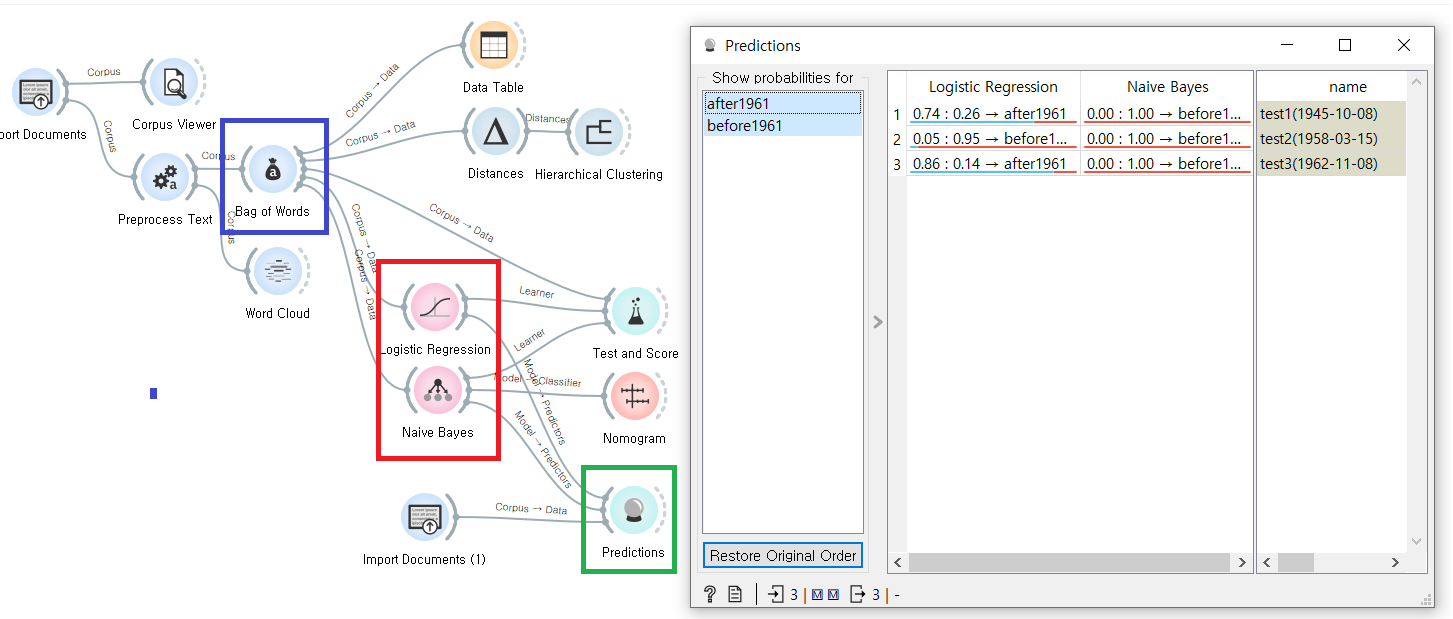
1961년 전후의 연설문 데이터를 가지고 Bag of Words 위젯으로 단어 빈도를 추출한 후, 두가지 분석모델(로지스틱 회귀, 나이브 베이스)을 활용해 분석하고 그 결과로 새로운 데이터가 1961년 전인지 후인지를 예측해보는 데이터 마이닝 모델이다. 자연스러운 분석 모델 워크 플로우다.
4) 교통사고 사망자 분석 모델

5) 주택 가격 예측 시스템

6) 청소년 비행 관련 예측 모델

7) 교통사고 사망, 부상 예측 모델

-4~7번은 지금까지 배운 것을 총망라하여 데이터를 기준으로 전반적으로 분석한 모델이다. 지금껏 많이 봐왔던 분석 패턴이기에 사실 특이사항은 크게 없다. 그래도 정리해보자면,
-실제 모델 생성에는 직접적 학습과 예측 뿐만아니라 EDA 과정도 상당히 중요하다. 어떤 식으로 데이터를 분석하고, 그 결과를 받아드려야할지는 사실 EDA 과정에서 결정된다고 해도 과언이 아니다.
-일반적인 방법으로 분석을 한 후 결과가 편향되게 나올 경우, 훈련데이터를 점검해야한다. 훈련데이터 자체가 편향되게 주어진 경우 이를 바탕으로 학습한 모델도 정확도가 떨어질 수 있기 때문에 편향된 데이터를 줄이는 과정이 필요하다.
-이 과정에서 Select Rows + Concatente 위젯이 사용된다. 그 결과를 바로 위 사진에서 찾아볼 수 있다. 훈련데이터 축소 후 전반적으로 모델의 성능이 나아졌다.
▷시스템 제작 후 느낀점
-예측은 회귀와 관련이 큼 (Linear Regression - 선형회귀 / Vector Auto Regressive -벡터자기회귀 등)
-회귀가 작동하려면 데이터에 특정한 경향성이 있음을 전제로 해야함.
-AI 솔루션 설계 단계는 데이터 선택 → 인공지능 모델 학습 → 학습 모델로 예측 → 예측 결과 활용 으로 구성됨.
-다중공선성 : 일부 예측변수가 다른 예측변수와 상관정도가 높아, 데이터 분석 시 회귀 계수의 분산을 증대시켜 부정적인 영향을 미치는 것.
-공공데이터 포털에서 실생활의 다양한 데이터를 얻을 수 있음.
-타겟 Feature 는 위젯 내에서 검은색으로 표현 / 위젯의 이름은 F2로 바꿀 수 있음.
-학습모델로 처리한 데이터를 저장해서 machine learning for kids / Entry 등의 사이트에서 추가로 활용할 수 있음.
-scratch3 에서 사전훈련한 모델이 확장패널로 생성되 새로운 블록으로 사용 가능.
-이원분류 해야하는 상황에서 한쪽의 훈련데이터가 비약적으로 많으면, 훈련데이터가 많은 쪽으로 편향학습을 하게됨
-따라서 Select Row / Concatenate 위젯을 활용해 클래스별 instance의 값을 맞춰주는게 중요함.
-즉 이 경우 과하게 많은 값은 학습데이터는 오히려 삭제해줘야 더 나은 예측 모델을 만들 수 있음. 학습데이터가 많다고 무조건 좋은 것이 아님.
'교육은 한 사람의 인생을 바꾼다 > AI교육' 카테고리의 다른 글
| 인공지능 구축에 있어서 알고리즘과 데이터 셋의 중요성 (2) | 2023.01.18 |
|---|---|
| AI 교육 평가 방법 (0) | 2023.01.17 |
| 완전 초짜 ORANGE 3 : 네트워크 분석 (0) | 2021.09.08 |
| 완전 초짜 ORANGE 3 : 시계열 분석 (0) | 2021.09.07 |
| 완전 초짜 ORANGE 3 : 연관 분석 (0) | 2021.09.06 |




댓글