
-데이터의 종류에는 크게 졍형 데이터와(회계데이터) / 비정형 데이터(유튜브, 카카오)가 있다.
-텍스트 마이닝 : 정해진 형식이 없는 비정형 데이터로부터 통계적 의미가 있는 개념이나 특성을 추출하고 이것들 간의 패턴이나 추세 등의 고품질 정보를 끌어내는 과정
▷핵심 용어 정리
-Corpus : 말뭉치 / 언어 연구를 위해 컴퓨터가 텍스트를 가공, 처리, 분석 할 수 있는 형태로 모아놓은 자료 집합
-Token : 기호에 의해 나눠진 기본 단위. 문장을 구분
-Parsing = Tokenization : 텍스트의 단어, 절을 분리해 분석해나가는 과정
-Stemming : 단어의 어간을 추출 / 단어의 어미를 자르는 어림 짐작 방법 ( pos 태그 미보존)
-lemmatization : 표제어 추출 ( pos 태그 보존)
-n-gram : 단어를 n개 단위로 묶어 확률적으로 표현해 둔 모델
-Stop word : 불용어 / 제외어 = 의미가 없는 단어 (the, a, of 와 같은 관사, 전치사, 접속사 등)
-document - term matrix : 문서 - 용어 메트릭스 / 문서에 있는 단어들을 행렬로 정리한 것
▷텍스트 마이닝의 과정
전처리 >> 문서요약 >> 문서분류 >> 문서군집 >> 특징추출
▷텍스트 마이닝 전처리(Preprocess text)
비정형 상태의 데이터들을 마이닝하기 적합한 상태로 가공하는 작업
▷Word Cloud

불러온 텍스트에서 단어의 빈도를 추출해 많이 쓰인 단어들은 중앙에 / 크게 배치하고 적게 쓰인 단어들은 외곽에 / 작게 배치한다. 그러나 단순히 Word Cloud 만 쓸 경우 특별한 의미를 담지 않은 조사, 관사 등의 불용어들을 핵심데이터로 추출하는 오류를 범한다. 따라서 전처리 과정이 필요하다.
▷Preprocess Text
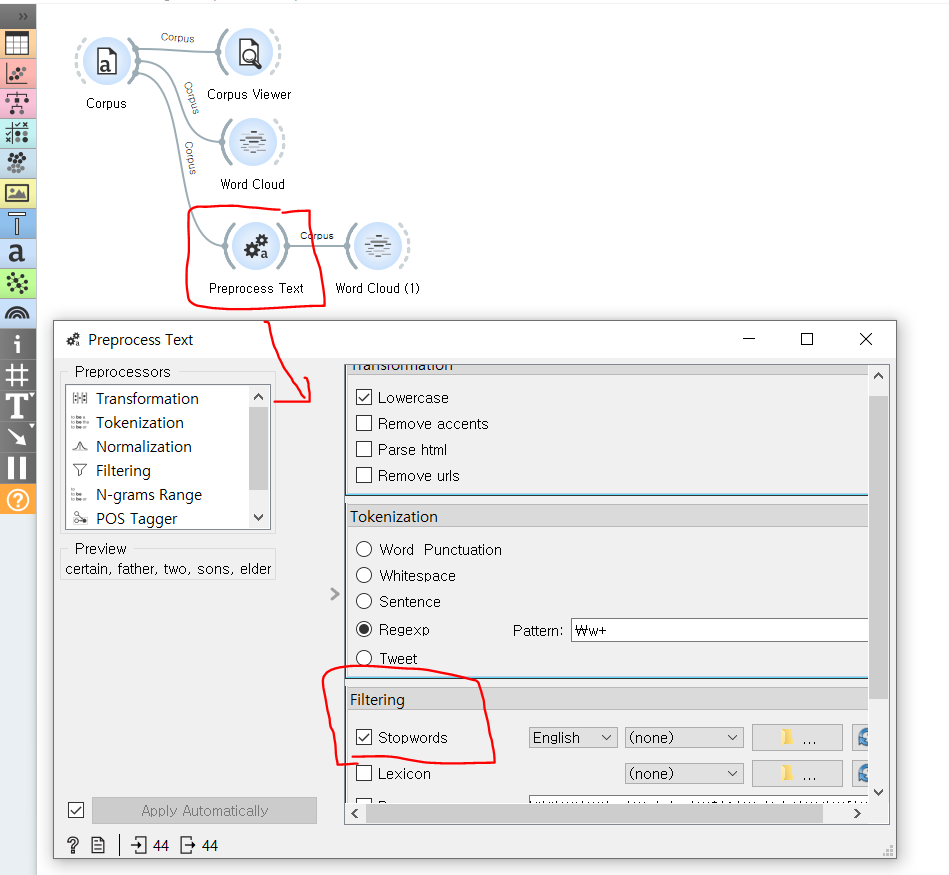
Preprocess Text 를 활용해 불용어를 제거할 수 있다. 이외에도 텍스트 전처리의 다양한 파이프라인(n-gram / 필터링 / 정규화)을 구성할 수 있다. stopwordlist.txt 파일을 만들어 직접 stopword 리스트를 만들 수 있다.

전처리를 통해 Word Cloud 를 만든 것과, 그냥 만든 Word Cloud 를 비교해보면 그 차이를 알 수 있다.
'교육은 한 사람의 인생을 바꾼다 > AI교육' 카테고리의 다른 글
| 완전 초짜 ORANGE 3 : 텍스트 마이닝 (군집화, 특징추출) (0) | 2021.08.25 |
|---|---|
| 완전 초짜 ORANGE 3 : 텍스트 마이닝 (문서요약, 분류) (0) | 2021.08.24 |
| 완전 초짜 ORANGE 3 : 데이터 분석의 기초 (0) | 2021.08.19 |
| 완전 초짜 VVVV : 다양한 기능 활용법 (1) | 2021.02.10 |
| 완전 초짜 VVVV : 미디(MIDI) 연주 (1) | 2021.02.09 |




댓글