
AI 교육대학원에 새로운 한 학기가 시작되었다. 이번에 배우는 과목은 '머신러닝에 교육적 활용'이다. 머신러닝에 대해 공부하기 위해 데이터를 분석할 수 있는 ORANGE 3 라는 프로그램을 활용한다.
https://orangedatamining.com/download/#windows
Download
Linux / Source Anaconda If you are using python provided by Anaconda distribution, you are almost ready to go. Add conda-forge to the list of channels you can install packages from conda config --add channels conda-forge and run conda install orange3 conda
orangedatamining.com
ORANGE 3 는 데이터를 분석하여 시각화해, 유의미한 인사이트를 발견하고 나아가 머신러닝에 적용하는 프로그램이다. 위 링크를 통해 무료로 다운받을 수 있다. 이런 다양한 데이터 분석 방식을 EDA(Eploratory Data Analysis) : 탐구적 자료 분석이라고 한다.
▶기초 용어 설명
-Instance : 한 객체. 말 그대로 하나의 개별적 데이터를 말한다. 예를 들면 한 사람.
-Feature : 한 객체의 속성값. 예를 들면 한 사람의 이름 / 성별 / 나이 등
-변수의 type : Text(문자형) / Categorical(범주형) / Datetime(날짜) / Numeric(숫자형)
-속성값의 role : Target(목표값) / Feature(목표에 영향을 주는 값) / Meta(목표에 영향은 못주지만, 참고할만한 값) / Skip(무시해도 되는 값)
▶EDA란?
-Exploratory Data Analysis = 탐구적 자료분석
-이전의 가설을 검증하기 보다는, 자료를 탐구함으로써 시작하는 통계적 분석 형태
-현실의 데이터를 모델과 알고리즘에 적합한 형태로 바꿀 때 효과적
-이 EDA의 과정에서 중요한 것이 '전처리(Prerprocess)' 과정
-질의 중심 EDA 과정 : 1)데이터에 대한 질문 / 2) 시각화, 변형, 모델링하여 답을 찾음 / 3) 새로운 질문 도출 >>> 이 과정을 통해 데이터, 패턴 판단에 Insight를 얻을 수 있음.
▶Scatter Plot : 산포도

Scatter Plot은 자료의 산포도를 보여주는 위젯이다. 산포도란 자료의 분산 정도를 직각 좌표계에 나타낸 그래프이다. Scatter Plot 을 더블 클릭해 x축, y축의 기준을 바꿀 수 있다. 또 이런 저런 세팅을 변경시킬 수 있는데 그 중에 흥미로웠던 것은 regression line 기능이다. regression line은 회귀직선을 긋는 것이다. 이와 관련해선 회귀분석을 다룰 때 좀 더 알아보도록 하자.
▶Outlier : '이상값'을 탐지하는 위젯

Outlier 위젯을 통해 기본 통계 정보 중 '이상값' 들을 탐색할 수 있다. 이런 이상값 탐색을 통해 잘못된 데이터나, 오류를 걸러낼 수 있다고 한다. 걸러내진 정도를 시각적으로 확인하기 위해 Scatter Plot 위젯과 함께 쓰면 좋다. Outlier 를 Scatter Plot 과 연결할 때, inlier / outlier / data 세 가지 중 한가지와 연결할 수 있다.
▶Distribution : 통계자료 분포의 시각화
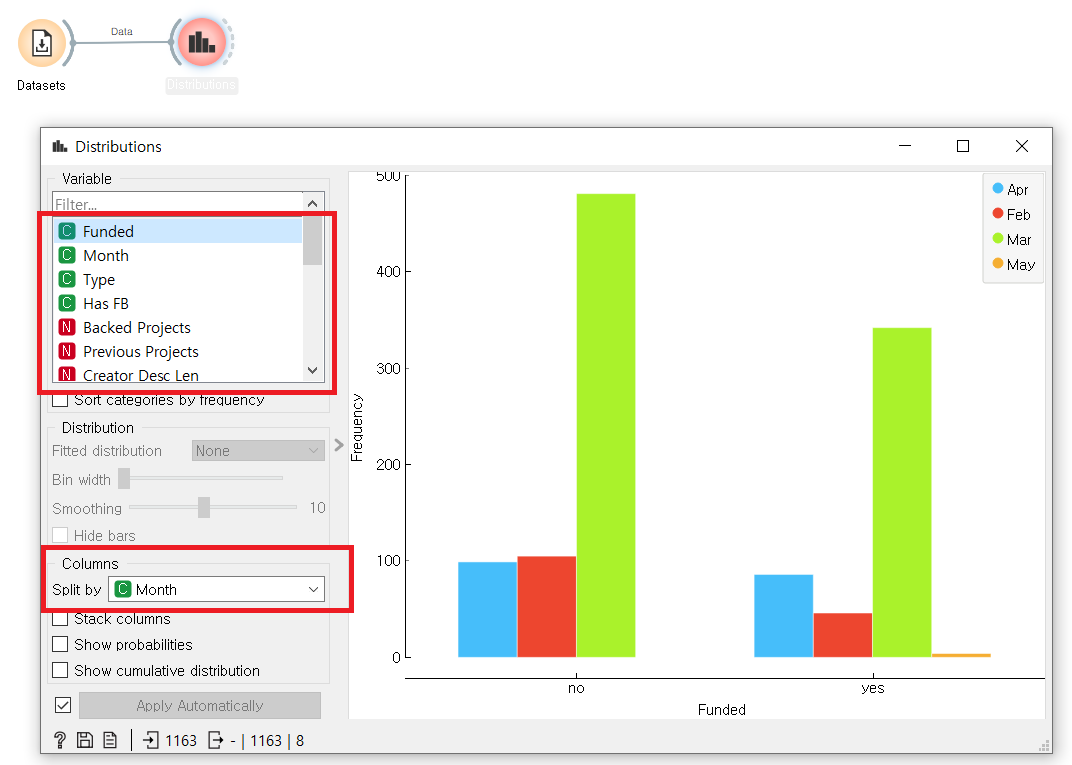
Filter 값과 Split by 기능을 이용해 다양한 데이터를 각기 다른 기준들로 분석하고 그 결과를 시각적으로 비교해 볼 수 있는 기능이다. 이 기능을 사용하면, 여러 데이터를 빠르고 쉽게 분석할 수 있다.
▶Box Plot : 통계의 5수치 (최솟값 / 1사분위수 / 중앙값 / 3사분위수 / 최댓값) 를 보여줌

Box Plot 를 통해 자주 사용되는 다양한 통계적 수치들을 쉽게 확인할 수 있다.
▶재미있는 샘플 데이터들 : Titanic / Iris
사용해본 샘플 데이터는 타이타닉과 아이리스이다. 타이타닉은 침몰된 배 타이타닉에 타고 있던 승객들의 나이 / 신분 / 성별 등의 데이터와 생존 / 사망 여부로 나눈 이진분류가 되어있는 데이터이다. 직관적이고 간단해서 재미있게 봤다.
또 하나의 데이터는 아이리스(붓꽃)의 3가지 종류에 따른 꽃받침과 꽃임의 길이와 넓이를 수록한 데이터이다. 나야 완전 초짜니까 당연히 처음 봤지만, 데이터 통계학에서는 꽤나 유명한 샘플 데이터라고 한다.
'교육은 한 사람의 인생을 바꾼다 > AI교육' 카테고리의 다른 글
| 완전 초짜 ORANGE 3 : 텍스트 마이닝 (문서요약, 분류) (0) | 2021.08.24 |
|---|---|
| 완전 초짜 ORANGE 3 : 텍스트 마이닝 (전처리) (0) | 2021.08.23 |
| 완전 초짜 VVVV : 다양한 기능 활용법 (1) | 2021.02.10 |
| 완전 초짜 VVVV : 미디(MIDI) 연주 (1) | 2021.02.09 |
| 완전 초짜 VVVV : 외부 파일을 3D 도형의 표면에 텍스처로 입히기 (1) | 2021.02.08 |




댓글